MapReduce Hadoop程序连接数据
这里有两个数据集合在两个不同的文件中,如下所示:
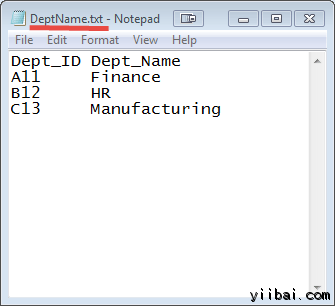
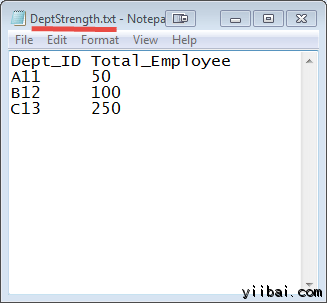
DEPT_ID 键在这两个文件中常见的。
目标是使用 MapReduce 加入来组合这些文件。
输入: 我们的输入数据集是两个txt文件:DeptName.txt 和 DepStrength.txt
前提条件:
- 本在线教程是在 Linux 上开发 - Ubuntu操作系统
- 已经安装的Hadoop(本在线教程使用2.7.1版本)
- Java的开发运行环境已经在系统上安装(本在线教程使用的版本是:1.8.0)
在我们开始实际操作之前,使用的用户 'hduser_'(使用 Hadoop 的用户)。
yiibai@ubuntu:~$ su hduser_
步骤
Step 1) 复制 zip 文件到您选择的位置
hduser_@ubuntu:/home/yiibai$ cp /home/yiibai/Downloads/MapReduceJoin.tar.gz /home/hduser_/ hduser_@ubuntu:/home/yiibai$ ls /home/hduser_/
操作过程及结果如下:


Step 2) 解压缩ZIP文件,使用以下命令:
hduser_@ubuntu:~$ sudo tar -xvf MapReduceJoin.tar.gz
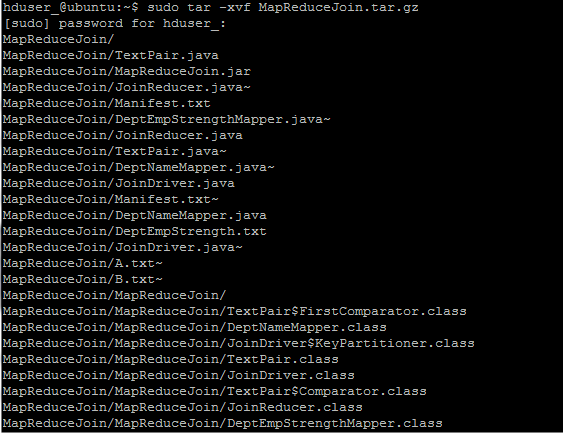

Step 3) 进入目录 MapReduceJoin/
hduser_@ubuntu:~$ cd MapReduceJoin/
Step 4) 启动 Hadoop
hduser_@ubuntu:~/MapReduceJoin$ $HADOOP_HOME/sbin/start-dfs.sh hduser_@ubuntu:~/MapReduceJoin$ $HADOOP_HOME/sbin/start-yarn.sh

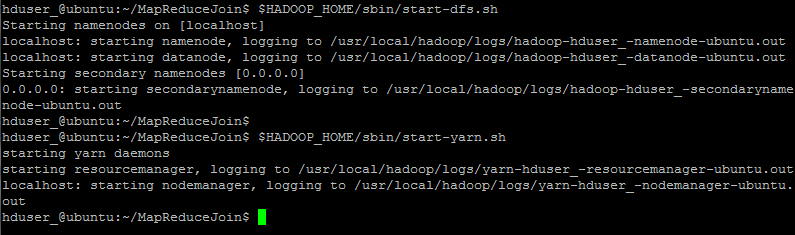
Step 5) DeptStrength.txt 和 DeptName.txt 用于此项目的输入文件
这些文件需要使用以下命令 - 复制到 HDFS 的根目录下,使用以下命令:
hduser_@ubuntu:~/MapReduceJoin$ $HADOOP_HOME/bin/hdfs dfs -copyFromLocal DeptStrength.txt DeptName.txt /
Step 6) 使用以下命令 - 运行程序
hduser_@ubuntu:~/MapReduceJoin$ $HADOOP_HOME/bin/hadoop jar MapReduceJoin.jar /DeptStrength.txt /DeptName.txt /output_mapreducejoin


Step 7)
在执行命令后, 输出文件 (named 'part-00000') 将会存储在 HDFS目录 /output_mapreducejoin
结果可以使用命令行界面可以看到:
hduser_@ubuntu:~/MapReduceJoin$ $HADOOP_HOME/bin/hdfs dfs -cat /output_mapreducejoin/part-00000


结果也可以通过 Web 界面查看(这里我的虚拟机的IP是 192.168.1.109),如下图所示:
现在,选择 “Browse the filesystem”,并浏览到 /output_mapreducejoin
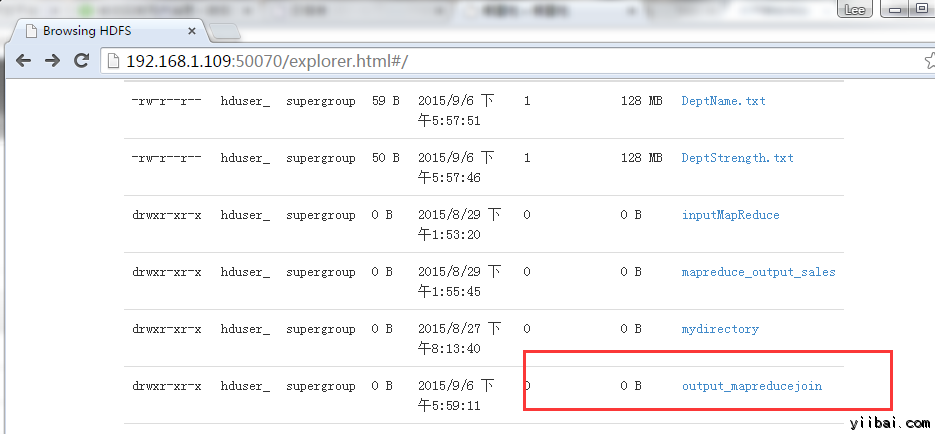
打开 part-r-00000
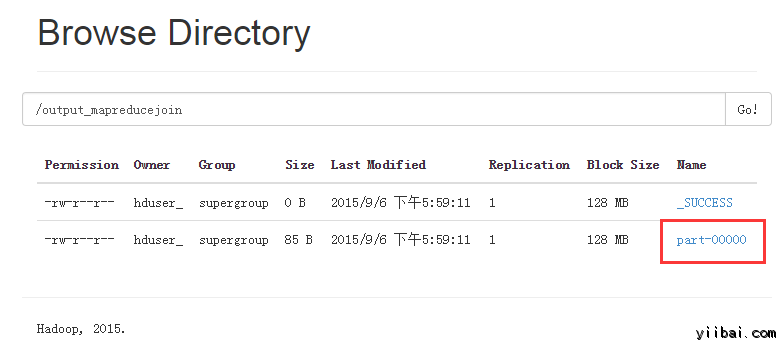

结果如下所示,点击 Download 链接下载:

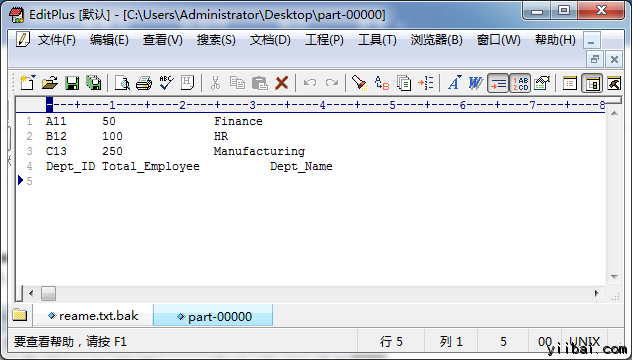
打开下载后的 文件,结果如下所示:

注:请注意,下一次运行此程序之前,需要删除输出目录 /output_mapreducejoin
$HADOOP_HOME/bin/hdfs dfs -rm -r /output_mapreducejoin
另一种方法是使用不同的名称作为输出目录。