TIKA元数据提取
除了内容,Tika还可以从一个文件中提取元数据。元数据是什么,但用文件所提供的附加信息。如果我们考虑一个音频文件,艺术家名,专辑名,标题下自带的元数据。
XMP标准
可扩展元数据平台(XMP)是用于处理和涉及到的文件的内容存储信息的标准。它是由Adobe系统公司的XMP创建提供了用于定义,创建和元数据的处理标准。可以嵌入该标准为多种文件格式,如PDF,JPEG,JPEG,GIF,JPG,HTML等。
Property 类
Tika使用属性类遵循XMP属性定义。它提供了PropertyType和值类型枚举捕获的元数据的名称和值。
Metadata 类
这个类实现了各种接口,如ClimateForcast, CativeCommons,Geographic, TIFF 等提供各种元数据模型的支持。此外,此类提供各种方法来提取一个文件的内容。
Metadata 名称
我们可以从它的元数据对象用的方法()提取一个文件的所有元数据的名称的列表。它返回所有的名字作为一个字符串数组。使用元数据的名称,就可以得到使用get()方法的值。它需要一个元数据的名称,并返回与它相关联的值。
String[] metadaNames = metadata.names(); String value = metadata.get(name);
使用解析法提取元数据
当我们分析一个使用文件parse(),传递一个空的元数据对象作为一个参数。这种方法提取指定的文件的元数据(如果该文件中包含有),并将它们放置在元数据对象。因此,在使用parse()解析文件后,就可以提取该对象的元数据。
Parser parser = new AutoDetectParser(); BodyContentHandler handler = new BodyContentHandler(); Metadata metadata = new Metadata(); //empty metadata object FileInputStream inputstream = new FileInputStream(file); ParseContext context = new ParseContext(); parser.parse(inputstream, handler, metadata, context); // now this metadata object contains the extracted metadata of the given file. metadata.metadata.names();
下面给出的是一个完整的程序,从文本文件中提取元数据。
import java.io.File; import java.io.FileInputStream; import java.io.IOException; import org.apache.tika.exception.TikaException; import org.apache.tika.metadata.Metadata; import org.apache.tika.parser.AutoDetectParser; import org.apache.tika.parser.ParseContext; import org.apache.tika.parser.Parser; import org.apache.tika.sax.BodyContentHandler; import org.xml.sax.SAXException; public class GetMetadata { public static void main(final String[] args) throws IOException, TikaException { //Assume that boy.jpg is in your current directory File file=new File("boy.jpg"); //Parser method parameters Parser parser = new AutoDetectParser(); BodyContentHandler handler = new BodyContentHandler(); Metadata metadata = new Metadata(); FileInputStream inputstream = new FileInputStream(file); ParseContext context = new ParseContext(); parser.parse(inputstream, handler, metadata, context); System.out.println(handler.toString()); //getting the list of all meta data elements String[] metadataNames = metadata.names(); for(String name : metadataNames) { System.out.println(name + ": " + metadata.get(name)); } } }
将以上代码保存为GetMetadata.java并在命令提示符处使用以下命令运行它:
javac GetMetadata .java java GetMetadata
注意:假设下面的图片是boy.jpg
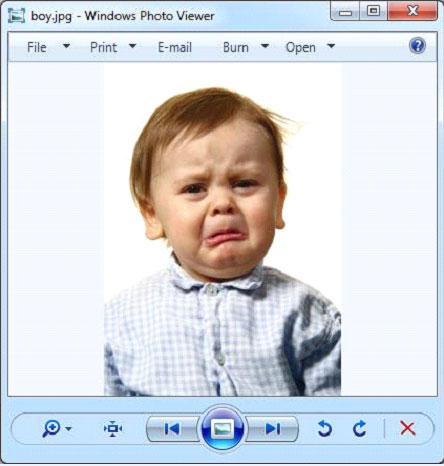
它提供了以下的输出:
Resolution Units: inch Compression Type: Baseline Data Precision: 8 bits Number of Components: 3 tiff:ImageLength: 1000 Component 2: Cb component: Quantization table 1, Sampling factors 1 horiz/1 vert Component 1: Y component: Quantization table 0, Sampling factors 1 horiz/1 vert Image Height: 1000 pixels X Resolution: 300 dots Original Transmission Reference: 53616c7465645f5fd22a84941585d89cc735d889c9d5ac58a01faf2c92ee3c6f9bcb38359bbe1eef Image Width: 714 pixels IPTC-NAA record: 92 bytes binary data Component 3: Cr component: Quantization table 1, Sampling factors 1 horiz/1 vert tiff:BitsPerSample: 8 Application Record Version: 4 tiff:ImageWidth: 714 Content-Type: image/jpeg Y Resolution: 300 dots
还可以得到想要的元数据值。
添加新的元数据值
可以添加使用元数据类的add()方法新的元数据值。下面给出的是该方法的语法。在这里要添加的作者名字。
metadata.add(“author”,”Tutorials yiibai”);
元数据Metadata类预定义的属性包括类,如ClimateForcast,CativeCommons,Geographic继承等,以支持各种数据模型的属性。下面示出的是从由提卡实施遵循XMP元数据标准的TIFF图像格式的TIFF接口继承了软件数据类型的使用。
metadata.add(Metadata.SOFTWARE,"ms paint");
下面给出的是演示如何将元数据值添加到一个给定文件的完整程序。这里的元数据元素的列表被显示在输出,这样就可以增加新的值之后,观察在列表中的变化。
import java.io.File; import java.io.FileInputStream; import java.io.IOException; import java.util.Arrays; import org.apache.tika.exception.TikaException; import org.apache.tika.metadata.Metadata; import org.apache.tika.parser.AutoDetectParser; import org.apache.tika.parser.ParseContext; import org.apache.tika.parser.Parser; import org.apache.tika.sax.BodyContentHandler; import org.xml.sax.SAXException; public class AddMetadata { public static void main(final String[] args) throws IOException, SAXException, TikaException { //create a file object and assume sample.txt is in your current directory File file = new File("Example.txt"); //Parser method parameters Parser parser = new AutoDetectParser(); BodyContentHandler handler = new BodyContentHandler(); Metadata metadata = new Metadata(); FileInputStream inputstream = new FileInputStream(file); ParseContext context = new ParseContext(); //parsing the document parser.parse(inputstream, handler, metadata, context); //list of meta data elements before adding new elements System.out.println( " metadata elements :" +Arrays.toString(metadata.names())); //adding new meta data name value pair metadata.add("Author","Tutorials Point"); System.out.println(" metadata name value pair is successfully added"); //printing all the meta data elements after adding new elements System.out.println("Here is the list of all the metadata elements after adding new elements "); System.out.println( Arrays.toString(metadata.names())); } }
将以上代码保存为AddMetadata.java类,然后从命令提示符下运行它:
javac AddMetadata .java java AddMetadata
假设 example.txt 有下列内容:
Hi students welcome to yiibai
它提供了以下的输出:
metadata elements of the given file :[Content-Encoding, Content-Type] metadata name value pair is successfully added Here is the list of all the metadata elements after adding new elements [Content-Encoding, Author, Content-Type]
设定值,用现有的元数据元素
可以设置值,使用set()方法在现有的元数据元素。使用set()方法设置的时间属性的语法如下:
metadata.set(Metadata.DATE, new Date());
还可以设置多个值,以使用set()方法的属性。使用set()方法多个值设定为作者属性的语法如下:
metadata.set(Metadata.AUTHOR, "ram ,raheem ,robin ");
下面给出的是一个完整的程序演示set()方法。
import java.io.File; import java.io.FileInputStream; import java.io.IOException; import java.util.Date; import org.apache.tika.exception.TikaException; import org.apache.tika.metadata.Metadata; import org.apache.tika.parser.AutoDetectParser; import org.apache.tika.parser.ParseContext; import org.apache.tika.parser.Parser; import org.apache.tika.sax.BodyContentHandler; import org.xml.sax.SAXException; public class SetMetadata { public static void main(final String[] args) throws IOException,SAXException, TikaException { //Create a file object and assume example.txt is in your current directory File file = new File("example.txt"); //parameters of parse() method Parser parser = new AutoDetectParser(); BodyContentHandler handler = new BodyContentHandler(); Metadata metadata = new Metadata(); FileInputStream inputstream = new FileInputStream(file); ParseContext context = new ParseContext(); //Parsing the given file parser.parse(inputstream, handler, metadata, context); //list of meta data elements elements System.out.println( " metadata elements and values of the given file :"); String[] metadataNamesb4 = metadata.names(); for(String name : metadataNamesb4) { System.out.println(name + ": " + metadata.get(name)); } //setting date meta data metadata.set(Metadata.DATE, new Date()); //setting multiple values to author property metadata.set(Metadata.AUTHOR, "ram ,raheem ,robin "); //printing all the meta data elements with new elements System.out.println("List of all the metadata elements after adding new elements "); String[] metadataNamesafter = metadata.names(); for(String name : metadataNamesafter) { System.out.println(name + ": " + metadata.get(name)); } } }
将以上代码保存为SetMetadata.java并在命令提示符下运行:
javac SetMetadata.java java SetMetadata
注意:假设sample.txt 有下列内容:
Hi students welcome to yiibai
在输出中,可以看到新添加的元数据元素。
metadata elements and values of the given file : Content-Encoding: ISO-8859-1 Content-Type: text/plain; charset=ISO-8859-1 Here is the list of all the metadata elements after adding new elements date: 2014-09-24T07:01:32Z Content-Encoding: ISO-8859-1 Author: ram, raheem, robin Content-Type: text/plain; charset=ISO-8859-1